Analysis of Frequently Used Articles
One of the primary KDA activities is the analysis of article reuse. Looking at the frequency of article reuse over a period of time will tell us what articles are being reused the most. These are high-value articles and therefore worthy of our attention. This, of course, is dependent on the accuracy of the knowledge workers' linking the resolution articles to the incidents or requests.
This technique is called a Pareto analysis. It is a frequency distribution of the number of times an article has been linked.
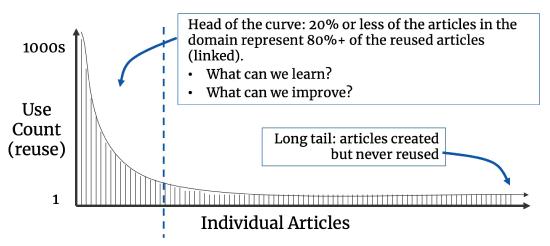 We see some predictable phenomena in looking at the Pareto analysis of articles linked in a knowledge domain. The frequency distribution of article reuse in a domain is always a power curve: the 80-20 rule applies. In every organization we have had the opportunity to work with on article reuse analysis, 80% of articles are rarely or never reused (the long tail). Of the remaining 20%, some are reused much more often than others (the head of the curve).
We see some predictable phenomena in looking at the Pareto analysis of articles linked in a knowledge domain. The frequency distribution of article reuse in a domain is always a power curve: the 80-20 rule applies. In every organization we have had the opportunity to work with on article reuse analysis, 80% of articles are rarely or never reused (the long tail). Of the remaining 20%, some are reused much more often than others (the head of the curve).
The pattern of article reuse in a domain is always interesting. A few questions to ask ourselves about the articles in the head of the curve:
- Are these highly used articles correct, accurate?
- Do these high-value articles adhere to our content standard?
- Are there articles in the long tail that address the same or similar issues found in the head of the curve?
- Are any of the issues candidates for root cause analysis and corrective action to remove the cause from the environment?
Once we have identified the most frequently reused articles in the domain, the next step is to see what we can learn by looking for patterns or clusters across the entire domain.
Identify Clusters
We want to look for patterns and clusters from two different perspectives. Are there common issues across multiple articles, and are there common causes/resolutions across multiple articles?
Identifying these two types of clusters across the entire domain can help us reduce ambiguity and duplicate articles, which will improve our ability to deliver relevant articles to the requestors.
Commercially available data mining tools can help by programmatically identifying clusters across a domain that may have thousands of articles. We should note that a consistent or common structure for our articles enables us to identify clusters by analyzing specific fields (title and issue/problem description or the resolution and cause fields) across a large collection of articles. The following outlines a manual process for identifying common symptoms and common causes.