Analyse häufig genutzter Artikel
Eine der Hauptaktivitäten der Themenbereichsanalyse ist die Analyse der Artikel-Wiederverwendung. Die Häufigkeit, mit der Artikel in einem Zeitfenster wiederverwendet werden, zu beobachten wird uns sagen, welche Artikel am häufigsten wiederverwendet werden. Das sind hochwertige Artikel und verdienen deshalb unsere Aufmerksamkeit. Das hängt natürlich von der Genauigkeit ab, mit der Wissensarbeiter die Lösungsartikel mit Vorfällen oder Anfragen verknüpfen.
Diese Technik heißt Pareto-Analyse. Es ist eine Häufigkeitsverteilung der Male, die ein Artikel verknüpft wurde.
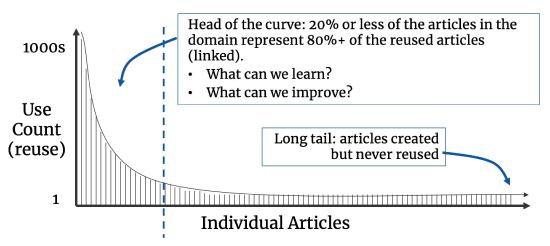 Wir sehen einige vorhersehbare Phänomene, wenn wir auf die Pareto-Analyse von Artikeln, die in einem Themenbereich verknüpft werden, schauen. Die Häufigkeitsverteilung der Artikelwiederverwendung in einem Bereich ist immer eine Leistungskurve: die 80-20-Regel trifft zu. In jeder Organisation mit der wir an Artikel-Wiederverwendungs-Analysen arbeiten durften, wurden 80% der Artikel selten oder nie wiederverwendet (Rattenschwanz). Von den verbleibenden 20% wurden manche öfter wiederverwendet als andere (Kopf der Kurve).
Wir sehen einige vorhersehbare Phänomene, wenn wir auf die Pareto-Analyse von Artikeln, die in einem Themenbereich verknüpft werden, schauen. Die Häufigkeitsverteilung der Artikelwiederverwendung in einem Bereich ist immer eine Leistungskurve: die 80-20-Regel trifft zu. In jeder Organisation mit der wir an Artikel-Wiederverwendungs-Analysen arbeiten durften, wurden 80% der Artikel selten oder nie wiederverwendet (Rattenschwanz). Von den verbleibenden 20% wurden manche öfter wiederverwendet als andere (Kopf der Kurve).
Die Muster der Artikelwiederverwendung in einem Bereich ist immer spannend. Ein paar Fragen, die wir uns selbst zu den Artikeln im Kopf der Kurve stellen sollten, sind:
- Sind diese oft genutzten Artikel richtig und zutreffend?
- Halten sich diese hochwertigen Inhalte an unseren Inhaltsstandard?
- Gibt es im Rattenschwanz Artikel, die dieselben oder ähnliche Probleme wie Artikel im Kopf der Kurve behandeln?
- Sind einige davon Kandidaten für Ursachenanalysen und korrigierende Handlungen, um die Ursache aus der Umgebung zu entfernen?
Sobald wir die am häufigsten wiederverwendeten Artikel eines Bereichs identifiziert haben, ist der nächste Schritt zu sehen, was wir daraus lernen können, uns die Muster und Cluster im Bereich anzusehen.
Cluster identifizieren
Wir wollen Muster und Cluster aus zwei Perspektiven betrachten. Gibt es gemeinsame Probleme in verschiedenen Artikeln und gibt es gemeinsame Ursachen/Lösungen in mehreren Artikeln?
Diese zwei Typen Cluster über den Bereich hinweg zu erkennen kann uns helfen, Ambivalenz und doppelte Artikel zu verringern, was unsere Fähigkeit, dem Fragenden relevante Artikel zu liefern, verbessert.
Kommerziell erhältliche Data Mining Werkzeuge können helfen, programmatisch Cluster in einem Bereich zu identifizieren, der tausende von Artikeln umfassen kann. Wir sollten anmerken, dass eine konsistente oder geteilte Struktur für unsere Artikel es ermöglicht, Cluster zu identifizieren, indem wir bestimmte Felder (Titel und/oder Problembeschreibung oder Lösungs- du Ursache-Feld) über eine große Artikelsammlung hinweg analysieren. Im Folgenden umreißen wir einen manuellen Prozess um gemeinsame Symptome und Ursachen zu identifizieren.