_(1).svg?revision=1)
Making Work Visible
Matching Work and People

Directly tied to the Practice of Connect, our ability to make relevant connections of work to people, people to people, and people to content is what makes Intelligent Swarming intelligent. We want to make work visible to the right resources on the first touch, or as close to first touch as possible, and make it easy for people to find the right people to work with when solving issues.
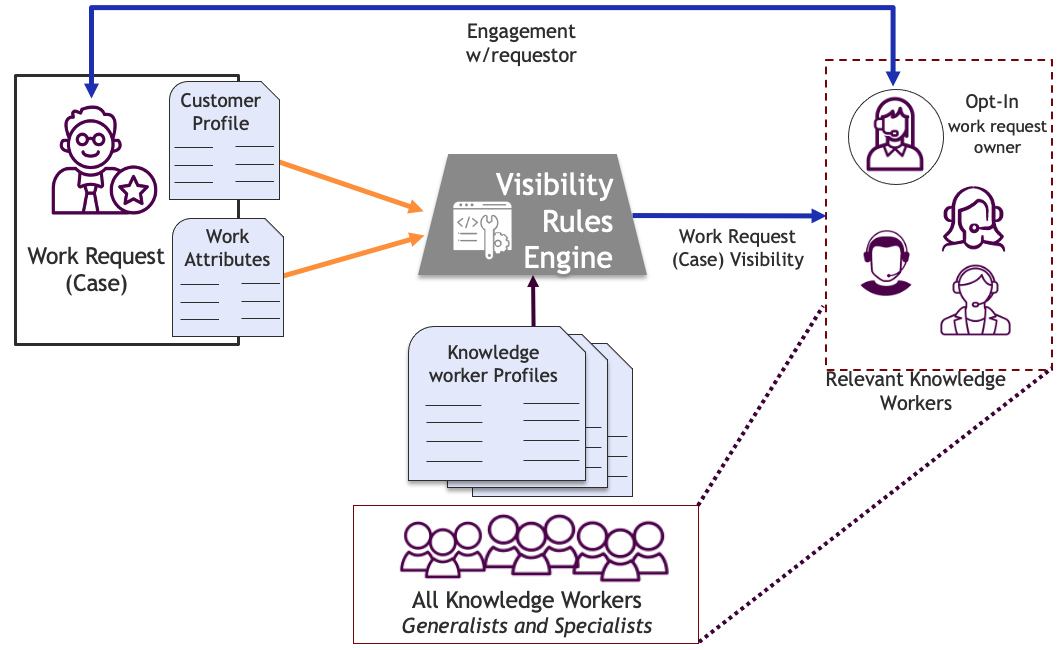
Based on what we know about the requestor and about the work, we want to enable visibility of the request to the people who are best able to solve it. This is done using a set of rules that we apply to an engagement trigger, based on attributes we capture in the People Profiles (for requestor and responder) and Work Profile. Designing these profiles is discussed in People Profiles.
Trigger for Engagement
The trigger for engagement starts with a work request through any channel. The trigger usually results in a Service Request, Case, Automated Machine Trigger, or similar event. The more we can capture during the engagement trigger, the better we can leverage our rules to best match people and work. Figuring out the attributes or characteristics of the work request early in the lifecycle of the engagement can be a challenge. If the requestor starts the process in a guided self-service mechanism, we have a number of opportunities to gather context about their intent or what they are trying to do. If the requests come in by phone or email, we often have little information about the requestor's intent.

Our degree of understanding about the work request directly impacts the size of the potential audience best able to handle the work.
Work Visibility: A Visibility Engine
The visibility engine leverages what we know about the work, what we know about the requestor, and what we know about potential responders, and applies business rules to make a decision about work visibility. Depending on the organization's size, breadth of products or services, maturity in capturing incoming context, and variations in contracts, the rules change drastically. However, in all cases it is important to factor in:
- Service Level Agreements / Paid Service Levels
- Exception Handling
- Contractual Obligations
At Member organizations with maturing Intelligent Swarming implementations, visibility happens through automation. This includes a detailed set of variables and attributes that feed a machine learning rules engine, which enables visibility of requests to those who are relevant. When starting out, a good way to learn is with a manual process using a small, diverse triage team or by utilizing workflow managers who do a quick assessment of the situation and have access to information about who in the organization knows what. This is not ideal, but it is good enough to get started! Either way, we need People Profiles to enable visibility to relevant work.
The end result of the visibility engine, whether manual or automated, offers visibility of work to those for whom the work is most relevant. When the work is visible to the most relevant people, a responder (knowledge worker) opts-in to select the work request and begins working the request.
When designing this process, take into account:
- The trigger for engagement from all of the available 'service' channels
- What we know about the request including work attributes and the attributes of the requestor
- What we know about the responders/knowledge workers
- How we will enable a Visibility Engine
- How a responder will opt-in to engage with the request/requestor
Consider 'offering to help' as not just a response to a person requesting help, but opting-in to assist on any work item. As a knowledge worker, I should be able to see ALL RELEVANT work, allowing me to help others without being prompted. This means that work that is selected by a responder is still visible to everyone it is relevant to.
Opt-in vs. Assignment
As we discuss in the section on motivation, autonomy is a key motivational factor in a healthy Intelligent Swarming system. People are more engaged when they have some level of control over the work they are interacting with. A visibility engine should make work visible to an appropriate subset of people, not be a way to simply assign work to a single person. However, there is a balance to be struck; a sense of ownership diminishes as the potential audience for the work grows. One collaboration workspace with everything visible will dilute people's ability to contribute.
For example, if there is one queue that all work enters and all responders monitor that queue, the sense of responsibility to respond may drop, since the responder needs to sort through a lot of details to find relevant work, and there is always 'someone else' available to take the work.
It is the responsibility of the responder to opt-in; they choose to take ownership of the request, or they offer help to the person who has taken ownership of the request. One of the ways we encourage this is by recognizing responders for the right behavior: for opting in to the "hardest" work, for offering assistance when they have information that could help, for requesting help at the right time. These things are all dependent on the right people having visibility to relevant work and relevant resources.
There are situations where an assignment of the request is appropriate (high severity or high impact issues, or a highly sensitive requestor). If the request meets certain criteria, the knowledge worker who is the best available resource to resolve the issue is expected to take ownership of the issue.
Caution: Do not turn a visibility engine into an assignment engine!
Manual Visibility / Matching
It may sound counterintuitive to call a manual process of classifying work an 'engine'. However, early in an adoption it is often difficult, if not impossible, to fully design an automated visibility engine; we just don't know enough about the system yet.
Starting manually with a 'triage' team who can make decisions based on data attributes, rules, and experience, and then make incoming requests visible to the right group of people is an option. This is also a great way to gain experience with the attributes required in our People and Work Profiles, and the rules that would make sense for eventual automation. We learn through doing!
Simplified example workflow
Designed by a Consortium for Service Innovation Member at the very start of their Intelligent Swarming journey, this company had some of their most senior resources act as "Triage Agents" during adoption. This allowed them to:
- Identify the attributes missing from People Profiles (Requestor Profiles & Knowledge Workers) and Work Profiles that will allow automation
- Identify gaps in the knowledge base that would allow the Triage team or Self-Service Search to better find content (enhanced KCS processes)
- Identify gaps in skill transfer with previous training materials, building a better onboarding process
- Identify and fix gaps in processes and thinking about how to best make work visible to the right resources.
Example flow for manual rules
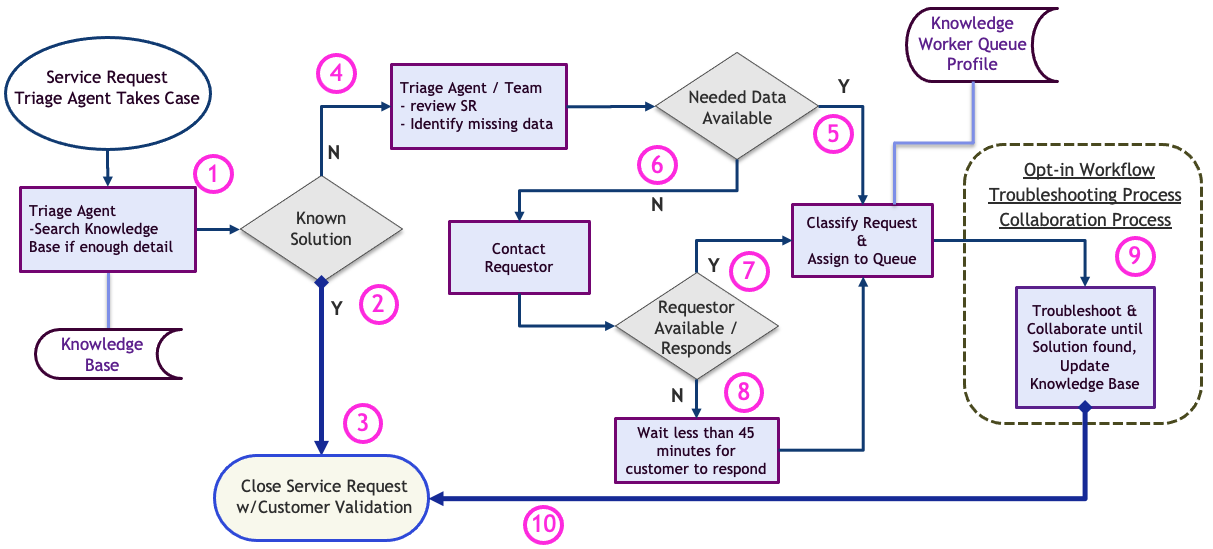
- Service Request (SR) is initiated and the Triage Agent assigns ownership to themselves. Triage Agent minimally works the service request by searching the Knowledge Base if enough information is available. The Triage Agent does not start to diagnose, troubleshoot, or engage the customer in problem solving.
- Triage Agent has all the information from customer to search Knowledge Base.
- If solution is found in the knowledge base, Triage Agent closes case, updates KB article if necessary, and attaches article to SR.
- Triage Agent does not have all information needed or solution cannot be found in Knowledge Base, SR moves on. The Triage Agent adds any details and identifies and documents any gaps in information needed.
- If all data is available, the Triage Agent classifies the attributes of the SR, referring to the Knowledge Worker Queue Profile, and assigns to the appropriate queue.
- If qualifying data is needed from the customer, the Triage Agent contacts the customer to retrieve the qualifying data. This is not troubleshooting information, but attributes such as: Severity, Contact details, products, or features involved.
- If the requestor is available, classify the attributes of the SR, refer to the Knowledge Worker Profile, and assign to the appropriate queue.
- If requestor is not available, wait no longer than 45 minutes and assign case to the Queue based on best judgement from available data. Troubleshooting Process will handle exceptions to incorrect queue assignment.
- Knowledge Workers follow Opt-in Workflow and Collaboration, Troubleshooting, and KCS Processes to work the SR.
- SR is closed after a solution is found and validated by the requestor.
In this example, there were also additional time limit guidelines. If the right information was available, it should take less than 10 minutes from Service Request open to assignment to the correct queue. If the right information was not available and the customer could not be reached, then the service request had to be assigned within 45 minutes. The triage team is not designed to do any troubleshooting beyond an initial Knowledge Base search and, at the end of a work day, the Triage team should have no Service Requests assigned to them. This process is truly designed to mimic an automated process in getting work visible to the best resources until an automated process can be implemented.
Automating Visibility / Intelligent Matching
There are many factors to consider in building an automated intelligent matching capability, but at the minimum, we must take into account People Profiles, Work Profiles, and the rules that act on those profiles. Cisco, one of our most sophisticated swarming examples, shared the following value, risk, relevance model they used for the attributes.
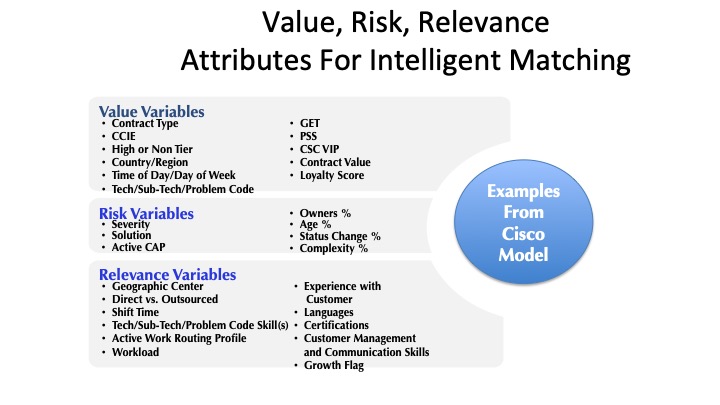
Cisco built a rules engine with some 50 business rules that used these attributes to manage visibility of relevant work to each of the support engineers. The same rules engine was used to identify the best resource available to help if a support engineer needed assistance. Cisco's system was designed by their engineers for their engineers.
While the variables in each category will be different and specific to each organization, thinking through Value, Risk, and Relevance can help identify what those relevant variables are.
Emerging digital automation capabilities will help us solve the challenge of automating intelligent matching. The Consortium's work on Predictive Customer Engagement
Making Work Visible in Action
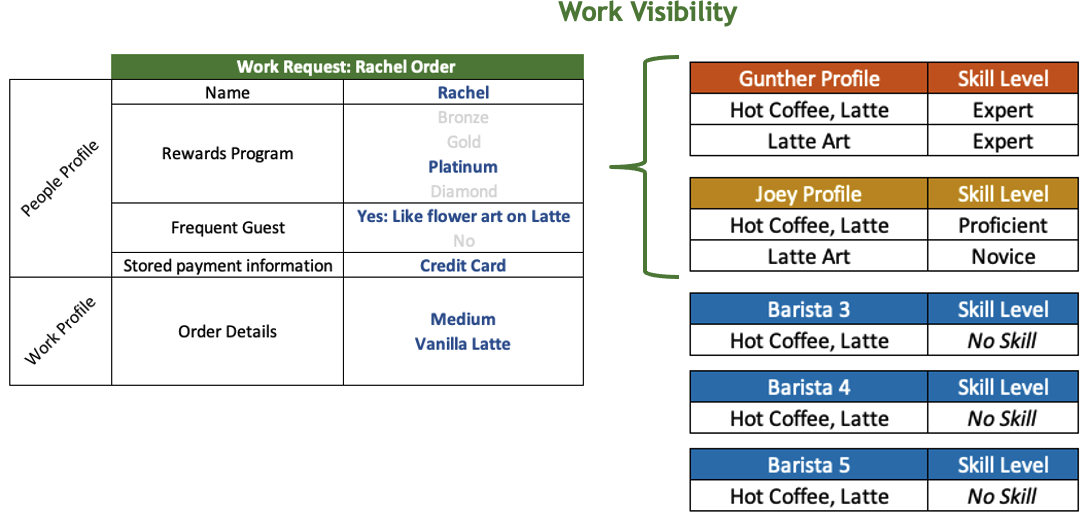
Morning Coffee Example
Back to our café, we now have a work request from Rachel that combines information about her profile and the work item, a vanilla café latte. Let's pretend this is a large café with many baristas working at the same time. We want Rachel's request to be visible to the subset of baristas with the skills to make her drink. Gunther and Joey are the baristas that can make lattes and have some skills with latte art. Rachel's work request would be visible to them and they would be eligible to 'opt-in' to complete the order.