Process
Knowledge workers collaborate quite naturally, often in spite of the artificial boundaries we have created and the measures we have used in traditional support. Our goal in designing the swarming process is to facilitate collaboration and optimize the use of our skills and resources. In this increasingly complex world, we can no longer always solve issues on our own. We need to collaborate with people who have different perspectives and expertise.
Intelligent Swarming is situational and therefore doesn’t follow a predefined process. The primary process looks simple: assess the issue, collaborate, solve the issue. However, the Intelligent Swarming process is not linear and the steps and resources involved will be different for each request. It's important to note that in an effective swarming model, people will play different roles based on the situation. While I might be the primary customer contact in this swarm, I might be a researcher or knowledge-capturer in the next.
Additionally how each organization implements Intelligent Swarming will be unique to that organization. In all cases, the process starts with a trigger (request, incident, ticket, case,...) and ends with the issue solved, while existing knowledge has been improved or new knowledge captured.
We’ll look at the key elements of the Intelligent Swarming process: intelligent matching and the collaboration process.
Intelligent Matching
Based on what we know about the requestor and the issue, we want to enable visibility of the request to the people who are best able to solve it. At Consortium member organizations that are more mature in their Intelligent Swarming implementations, this has been done through automation. Often this includes a detailed set of variables and attributes that feed a rules engine, which enables visibility of requests to those who are relevant. Most organizations, however, start with a manual process using a small diverse triage team or by utilizing workflow managers who do a quick assessment of the situation and know or have access to information about who in the organization knows what. This is not ideal - but it is good enough to get started! Either way, we need People Profiles to enable visibility to relevant work.
One of the challenges in building an intelligent matching engine is figuring out the attributes or characteristics of the issue. If the requestor starts the process in our self-service mechanism we have a number of opportunities to gather some context about their intent or what they're trying to do. If the requests come in by phone, we have very little information about the requestor's intent. This is where workflow managers or a triage function is necessary in order to understand the request and get it to the most appropriate resource.
Opt-in vs Assignment
As we discuss in the section on motivation, autonomy is a key motivational factor in a healthy swarming model. Intelligent Matching is ideally a way to manage visibility of work to those for whom the work is relevant or of interest. It is the responsibility of the knowledge worker to "opt-in;" they choose to take ownership of the request, or they offer help to the person that has taken ownership of the request. There are situations where an assignment of the request is appropriate (high severity or high impact issues, or a highly sensitive requestor). If the request meets certain criteria, the knowledge worker who is the best available resource to resolve the issue is expected to take ownership of the issue.
Thoughts on Automating Intelligent Matching
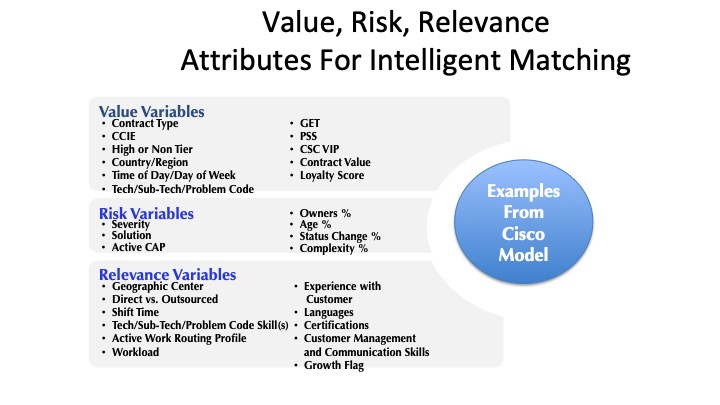 There are many factors to consider in building an automated intelligent matching capability. The three key elements are: the attributes of the issue, the attributes of the people (People Profiles), and the rules that act on those attributes. Cisco, one of our most sophisticated swarming examples, shared the following value, risk, relevance model they used for the attributes.
There are many factors to consider in building an automated intelligent matching capability. The three key elements are: the attributes of the issue, the attributes of the people (People Profiles), and the rules that act on those attributes. Cisco, one of our most sophisticated swarming examples, shared the following value, risk, relevance model they used for the attributes.
We offer this only as an example for your consideration. Each organization will need to come up with the list of attributes that are important for them.
Cisco built a rules engine with some 50 business rules that used these attributes to manage visibility of relevant work to each of the support engineers. The same rules engine was used to identify the best resource available to help if a support engineer needed assistance. Cisco's system was designed by engineers for engineers.
We hold great hope that emerging digital automation capabilities will help us solve the challenge of automating intelligent matching.
Designing the Collaboration Process
Some questions we need to consider when designing the Intelligent Swarming process:
- What is the scope of the collaboration? (all the knowledge workers from the old tiers of support (Levels 1/2/3), Engineering team, Sales, Partners, community members?)
- How are we going to get the most relevant responder on the request on the first touch?
- When the knowledge worker needs help, how do they find the most relevant people to collaborate?
- When someone is able to help, how do we enable them to offer help?
- How do we capture what we are learning? How do we ensure that we are using, improving, and if it doesn't exist, creating knowledge?
- How do we recognize those who are good at collaboration?
When designing the collaboration process, scenarios (or user stories) can help in designing the process. Below we describe the basic seven scenarios that are helpful as a starting point. The team of knowledge workers designing the processes will almost always come up with variations on these, or their own scenarios, based on the nature of the work they do.
The Intelligent Swarming process is best designed by the people who will be collaborating: the knowledge workers. And, we should expect that we will iterate on the process as we get some experience with it.
It is always a question as to whether we should design the ideal collaboration process (without regard to current platform functionality) or design the process based on our current platform functionality. The goal of the design session is to define just enough to get started with our current functionality. The experience we gain by trying it - even if much of it is manual - will give us an informed view of what the ideal process would be. For more on this see the Tools and Integration section.
Seven Process Scenarios
The following seven process scenarios have proven to be helpful when designing the Intelligent Swarming collaboration process. Think through these processes with the people who will be collaborating: how can we currently build a collaboration process around these scenarios? It can be helpful to separate these into synchronous (I need help in real time) and asynchronous (later is okay) processes.
- I need help (and I have searched the knowledge base)
- On a live call
- With a specific question
- I know who could answer it
- I need help
- On a live call
- With a specific question
- I don't know who could answer it
- I need help
- On a live call
- I have no idea about how to pursue resolution
- I need help
- In research mode (offline)
- I don't know who could help
- I see a request for help
- How do I know someone is asking for help in an area relevant to me?
- How do I respond?
- I see an incident (that someone else has taken ownership for) that I know the answer to.
- How do I find the incident?
- How do I offer help?
- How do I find or see open/available requests that are relevant to me?
Learning, Capturing Knowledge, and Sharing
As we mentioned earlier, knowledge is an important consideration in each scenario. Having the team identify the points in the process where knowledge practices play a role must be part of the process maps. When should we be searching and reusing knowledge, updating existing knowledge, and if it doesn't exist, creating knowledge articles? A simple and perhaps obvious example is that the process map for a knowledge worker requesting help should include searching the knowledge base before the request is made. It is critical that we capture - in the moment - what we learn as we collaborate. There is seldom time or motivation to update the knowledge base after the fact.
The collaboration in the swarm ends with a resolution that solves the issue of the requester. If the organization that adopts Intelligent Swarming has already adopted KCS, it is a natural step to update or create a knowledge article as part of this process. If KCS has not been adopted, using, improving, or capturing knowledge as part of the collaboration process will need some special attention.
For an exceptionally complex, critical, or pervasive issue, an after action review (AAR) might be appropriate. In Agile terms, this is a retrospective. This evaluation is done shortly after the swarm has solved the issue and before the swarm will be disbanded. Often facilitated by someone outside the team, the retrospective will look at the process of collaboration and outcome. How did it go? What can we learn for the next or similar situations? Did we collaborate too late, too soon? Did we engage the best resources available at the time? Do we need to improve the collaboration process or tools? The retrospective is not meant to assign blame, but rather to learn and improve.